
Any seasoned web developer knows what an uptime monitoring service is and the key role it has when deploying an application in a production environment: the ability to constantly check out the availability and/or reachability of the web app over time is easily among the most important things to have to ensure that your users are (and will always be) able to access the service.
This (almost) undeniable development need can be handled in the following ways:
- Using third party control tools such as Pingdom, Monitis, Uptime Robot, StatusCake and other similar services: for those who don't know about them, these are external uptime & performance monitoring services that can be used to send one or more requests at regular intervals (e.g. every 5 minutes) and send SMS, E-Mail and/or Push notifications if the receiving service - our web application - is unavailable. These services are basically SaaS and can be free or subscription-based (usually they have a free plan and one or more premium plans that require a monthly fee) depending on the features they provide: number of programmable tests, minimum execution interval time, and so on.
- Developing an internal monitoring system, i.e. a dedicated web-based service installed within the same production environment as the web application we want to check.
Uptime & Availability
Entrusting the uptime check of our web application's pages and/or APIs to a third-party service - which is obviously installed outside the server farm hosting the application to check for - is undoubtedly an excellent choice for at least two main reasons:
- The monitoring service won't be affected by any crashes that may occur within the server farm itself: in other words, we won't take the risk that it becomes unavailable along with the service it has to control, thus losing the opportunity to alert us.
- The monitoring service won't be affected by any "special rule" that may exist within the internal networks of the server farm (routing, VPN/firewall/proxy configurations, redirections, etc.) and can therefore perform "real" tests, similar to the real experience of those who are connecting to our systems from outside.
This, needless to say, will only work well if the third-party service is sufficiently reliable.
This uptime control methodology through third-party SaaS is arguably more effective than a monitoring system developed internally, yet it has some limitations:
- Third-party checks are always carried out through calls sent through ports and/or standard protocols - such as HTTP requests, ICMP requests and so on; although being more than enough for an high-level uptime checking, such method doesn't allow to check the correct functioning of complex functions at the back-end level. This kind of problem can be easily overcome by developing special "test pages" and exposing them to the WWW, yet such workaround - if not done properly - might raise an additional security problem (see below).
- To be able to perform the checks, the third-party service must be able to access the pages and/or APIs they have to monitor: this isn't a problem for publicly accessible pages such as the home page or a login page; however, it can become a critical security issue for more in-depth test pages (see above point) which could easily become the subject of attack: for example, a page that issues a series of SQL queries to one or more databases to check the availability of the SQL Service, the table status and/or the data consistency could be an ideal target for a DDoS attack. Although these third-party services offer a wide range of workarounds to overcome such problem(POST parameters, bearer token, caller IP whitelist etc..), a single configuration mistake is all it takes to open a dangerous security hole in your infrastructure.
It goes without saying that an internal, manually-developed control system is most likely protected against these kind of issues. All in all, we could say that the best solution is to use both approaches in a complementary way, entrusting high-level uptime monitoring to third-party services and performing the most complex checks with an internal control system unaccessible from the web - except for a single page to run an uptime check on the control service itself.
Elmah.io
In this complex scenario comes elmah.io, a Error Management, Deployment Tracking and Uptime Monitoring tool with the main goal of combining internal and external uptime and availability checks in a single, centralized monitoring platform.![]()
Among the many features made available by elmah.io, we would like to delve into the following aspects:
- An external uptime monitoring system, similar to those provided by the services mentioned early on (Pingdom, StatusCake & more): in short words, a standard availability check with a notification system that will alert the administrators in case of downtime.
- An internal error tracking & logging system, carried out by installing a special ASP.NET package within our ASP.NET, ASP.NET MVC or .NET Core application. Once installed, this middleware library will intercept all the exceptions raised by our application, making them available through a special web interface and sending (optionally) a timely notification and / or a daily summary of all errors to one or more e-mail addresses.
In our opinion, the real added value of elmah.io is given by the combination of these two aspects: the external uptime monitoring keeps us informed about the reachability and availability of our web site, while the internal error tracking allows us to have immediate news of any application crash - with the invaluable opportunity to view the details of the exception directly from the web.
The screenshot below shows the Overview page of a typical project added to elmah.io: a typical dashboard containing the various errors found over time, together with their related info (affected browsers, frequency / incidence, URL, & more).
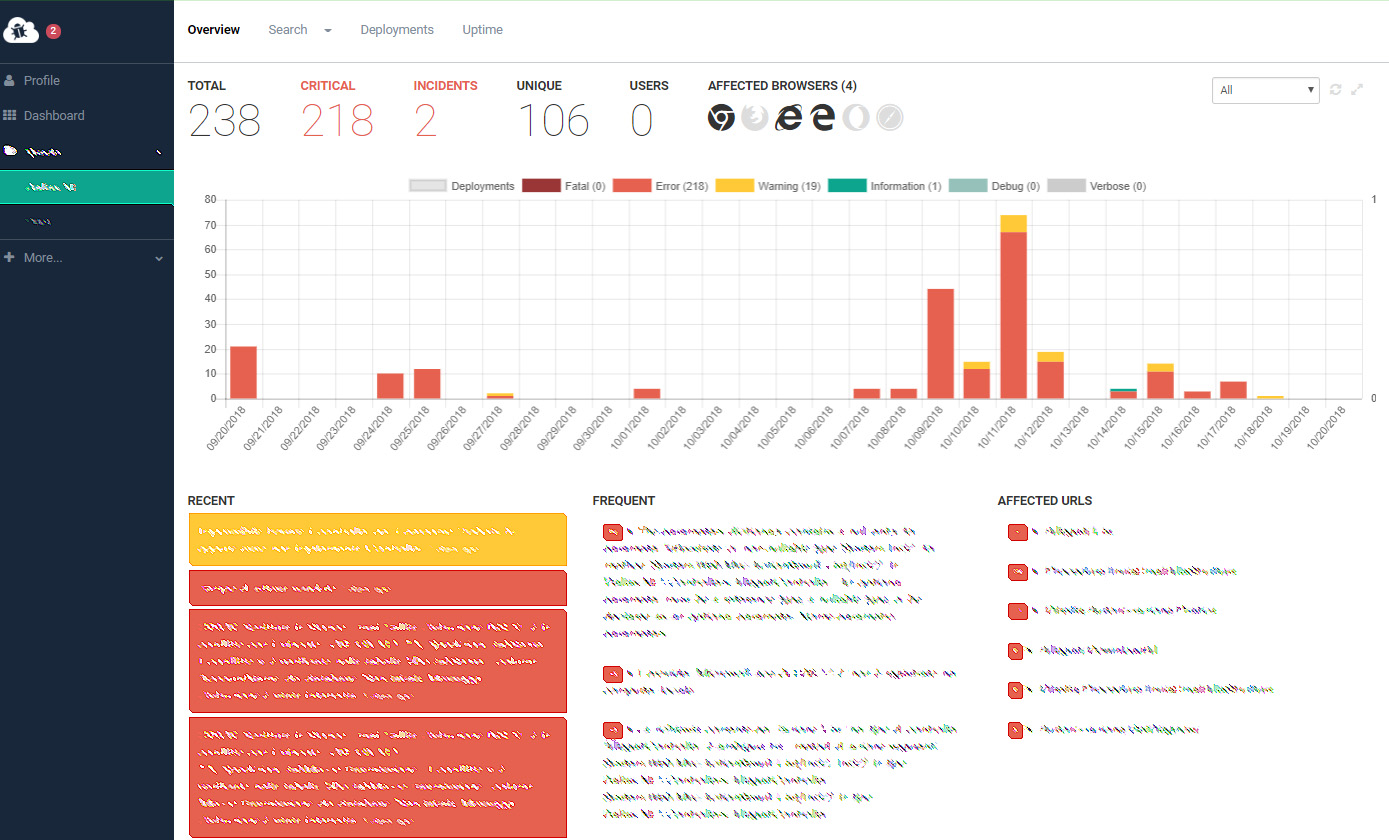
A more detailed, in-depth search can be done through the Search page, which allows to identify the various exceptions thrown by the app through google-like full-text queries and various filters (by date, by type of error, etc..).
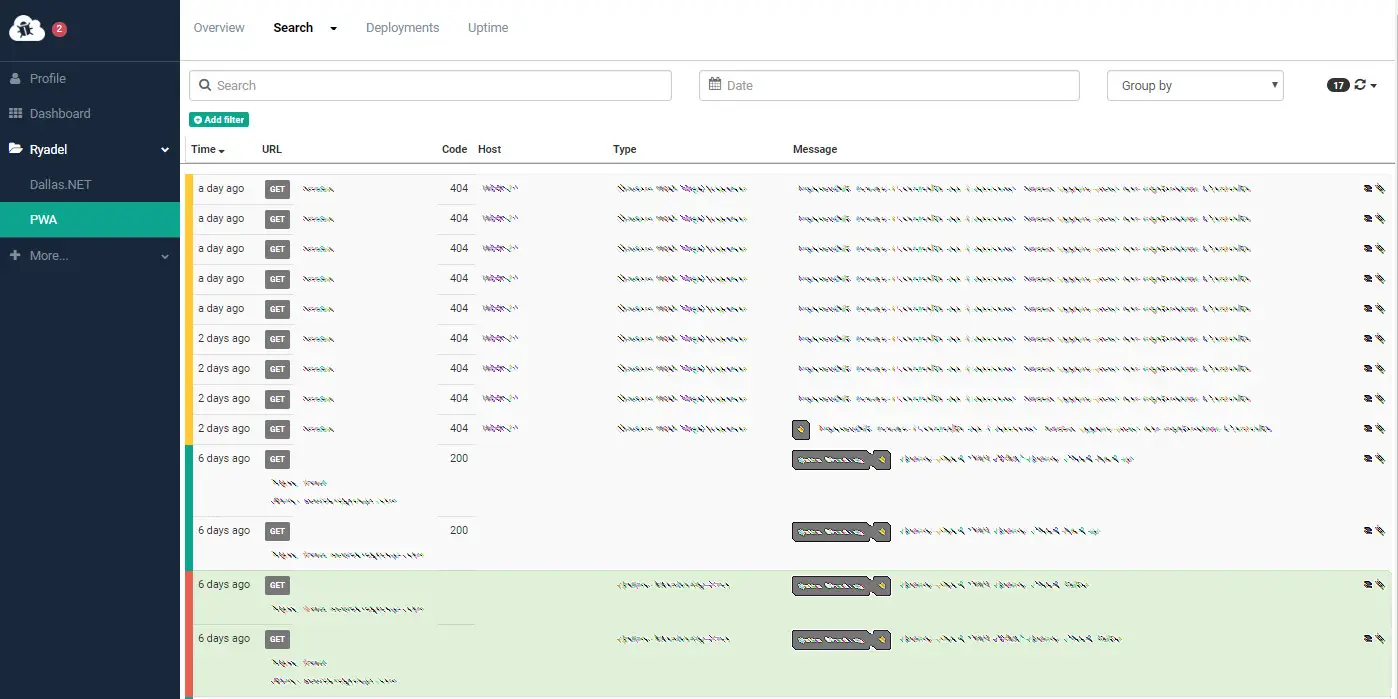
Installation
Installing elmah.io within an existing ASP.NET web application is an extremely simple task: all we need to do is to create an account on the elmah.io website, choose one of the available pricing plans and add the project to the service using the web interface. Once done, the service will bring us to a installation page containing all the instructions we need to install the error logging package on our choosen framework (ASP.NET, ASP.NET MVC, ASP.NET Core & more); it will also give us the required API KEY and LOG ID that we'll need to manually add within the application's Web.config file:
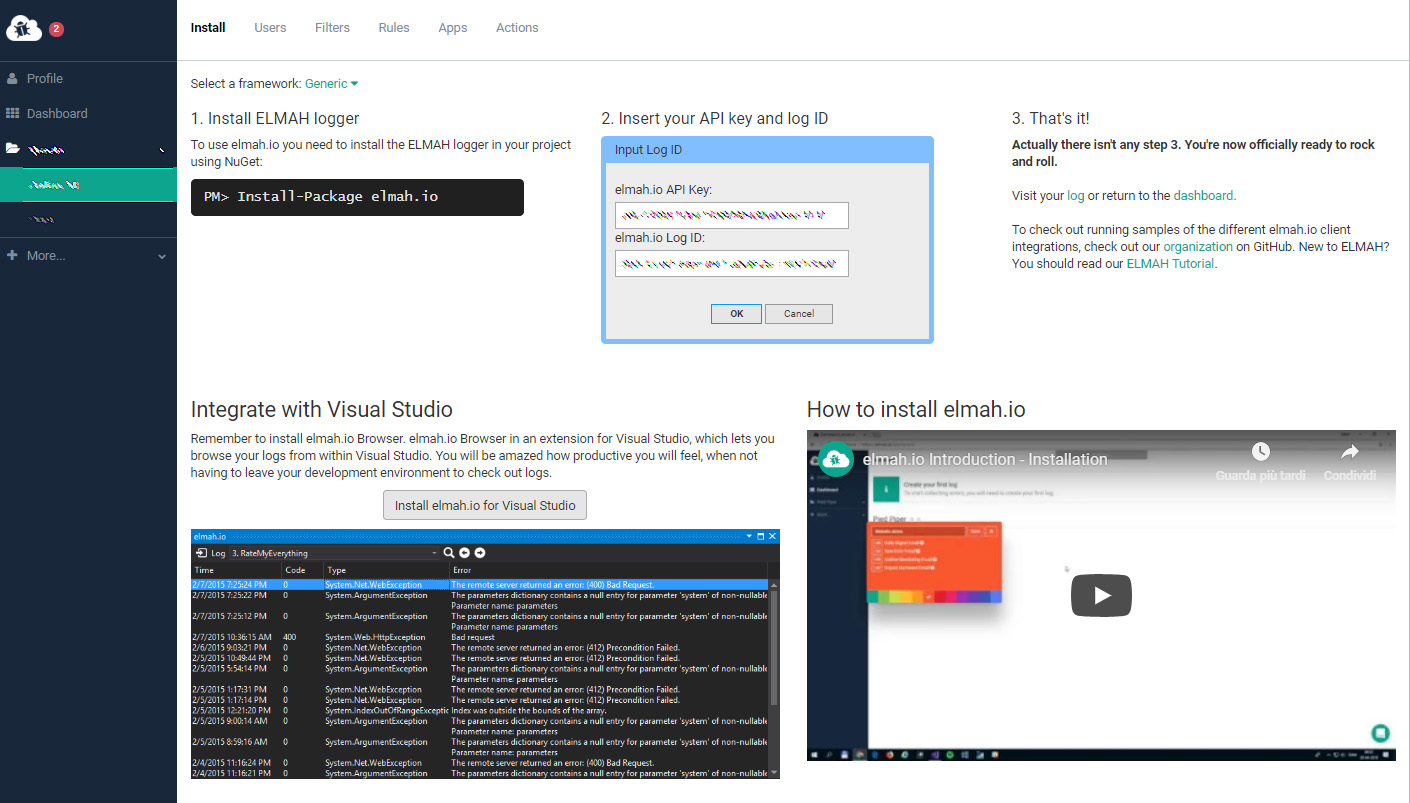
If we're using NuGet, the software installation will require a single line of code to write into the Package Manager Console:
|
1 |
PM> Install-Package elmah.io |
Visual Studio users will also benefit from a special extension (elmah.io per Visual Studio) that allows a seamless integration of elmah.io within the Visual Studio GUI: such integration will allow developers to view the elmah.io error logs directly from the development environment GUI.
The whole installation and configuration process is shown in details in the following YouTube video:

Pricing
The various subscription plans have an increasing pricing depending by the given set of features: the number of developers that can be assigned to each project, the log retention period and other optional tools. There are also special subscription programs (including NFR licenses, etc.) for startups, small businesses, MVPs and open-source projects.
Conclusions
Before writing this review we installed elmah.io on two rather important ASP.NET MVC projects for about two months: the overall experience we got was extremely positive. The error tracking GUI allowed us to perform the review & analysis of various bugs that would have been hard to reproduce in a development environment - eventually helping us to fix them. Being able to watch the Stack Trace produced by a real user behavior was definitely a great advantage.
Therefore, our final evaluation is extremely positive: the developers came out with a great tool that could be very useful to anyone interested in improving their testing and monitoring awareness on the software they develop and release: a strategic choice that now is more important than ever, considering the absolute importance of error tracking these days.
