


Table of Contents
As you might already know, plagiarism detection is the process - or the technique, if you prefer - of locating instances of plagiarism within an abstract, a document or any other text-based work. Plagiarism is something that has always existed since ancient times: however, thanks to the advent of modern technologies - the web in the first place - and Content Management Systems, which make it easier to plagiarize the work of others, it quickly escalated to a widespread phenomenon.
Plagiarism detection processes can be either manual or software-assisted: manual detection is not ideal, though, as it often requires substantial effort and excellent memory - which mean, high costs, especially for a huge amount of documents to check; for this very reason, software-assisted detection is almost always the way to go, as it allows vast collections of documents to be compared to each other, making successful detection much more likely. However, both control systems can be easily countered by manual or automatic techniques that rely on word substitutions and/or word order changes within the various sentences, thus making the plagiarism detection a much harder task: such anti-antiplagiarism technique is called rogeting. The battle between plagiarism detection and rogeting kind of resembles the "eternal" struggle between viruses and antivirus software and is mostly fought by very powerful algorithms.
In this post, we'll try to briefly explain the most common approaches implemented by most systems for text-plagiarism detection, and also spend a couple of words about rogeting techniques. If you're looking for free plagiarism checker tools, we strongly suggest taking a look at our 10 free anti-plagiarism detection tools list. In case you've been looking for rogeting tools instead, sadly we can't help you: you should definitely write your own, original text instead (especially if you're a student) or, if you are really unable to deal with such task, seek the help of a certified writing service such as Writix. It won't be written by you, yet at least it won't be an abuse of someone else's work.
Anti-Plagiarism
Anti-plagiarism solutions are typically split into two different detection approaches: external and intrinsic.
- External detection systems compare a suspicious document with a reference collection, which is a set of documents assumed to be genuine: the submitted text is compared with each one of these documents to produce one or multiple metrics (words, paragraphs, sentences, and so on) that calculates how much "distance" there is between the two.
- Intrinsic detection systems analyze the submitted text without performing comparisons to external documents trying to to recognize changes in the unique writing style of an author, which could be an indicator for potential plagiarism: such an approach is often used in mixed analyses - where humans and computers work together - since it's arguably not capable of reliably identifying plagiarism without human judgment.
The figure below (source: Wikipedia) depicts all detection approaches in use nowadays for computer-assisted plagiarism detection:
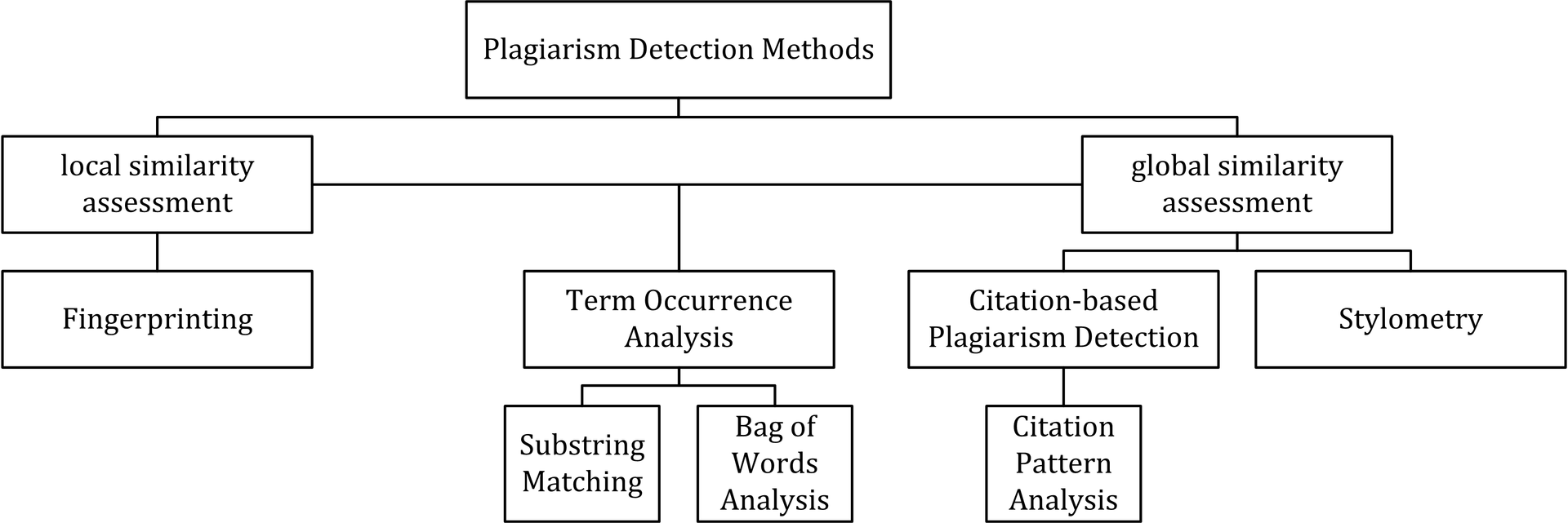
As we can see, the various approaches are split into two main "branches", characterized by the type of similarity assessment they undertake: global or local.
- Global similarity assessment approaches use the characteristics taken from larger parts of the text or the document as a whole to compute similarity.
- Local assessment approaches only examine pre-selected text segments as input.
In the next paragraphs, we'll briefly summarize each one of them (source: Wikipedia).
Fingerprinting
Fingerprinting is currently the most widely applied approach to plagiarism detection: this method forms representative digests of documents by selecting a set of multiple substrings (n-grams) from them. The sets represent the fingerprints and their elements are called minutiae. A suspicious document is checked for plagiarism by computing its fingerprint and querying minutiae with a precomputed index of fingerprints for all documents of a reference collection. Minutiae matching with those of other documents indicate shared text segments and suggest potential plagiarism if they exceed a chosen similarity threshold. Computational resources and time are limiting factors to fingerprinting, which is why this method typically only compares a subset of minutiae to speed up the computation and allow for checks in very large collections, such as the Internet.
String matching
String matching is a prevalent approach used in computer science. When applied to the problem of plagiarism detection, documents are compared for verbatim text overlaps. Numerous methods have been proposed to tackle this task, of which some have been adapted to external plagiarism detection. Checking a suspicious document in this setting requires the computation and storage of efficiently comparable representations for all documents in the reference collection to compare them pairwise. Generally, suffix document models, such as suffix trees or suffix vectors, have been used for this task. Nonetheless, substring matching remains computationally expensive, which makes it a non-viable solution for checking large collections of documents.
Bag of words
Bag of words analysis represents the adoption of vector space retrieval, a traditional IR concept, to the domain of plagiarism detection. Documents are represented as one or multiple vectors, e.g. for different document parts, which are used for pairwise similarity computations. Similarity computation may then rely on the traditional cosine similarity measure, or on more sophisticated similarity measures.
Citation analysis
Citation-based plagiarism detection (CbPD) relies on citation analysis and is the only approach to plagiarism detection that does not rely on the textual similarity. CbPD examines the citation and reference information in texts to identify similar patterns in the citation sequences. As such, this approach is suitable for scientific texts, or other academic documents that contain citations. Citation analysis to detect plagiarism is a relatively young concept. It has not been adopted by commercial software, but a first prototype of a citation-based plagiarism detection system exists. Similar order and proximity of citations in the examined documents are the main criteria used to compute citation pattern similarities. Citation patterns represent subsequences non-exclusively containing citations shared by the documents compared. Factors, including the absolute number or relative fraction of shared citations in the pattern, as well as the probability that citations co-occur in a document are also considered to quantify the patterns’ degree of similarity.
Stylometry
Stylometry subsumes statistical methods for quantifying an author’s unique writing style and is mainly used for authorship attribution or intrinsic CaPD. By constructing and comparing stylometric models for different text segments, passages that are stylistically different from others, hence potentially plagiarized, can be detected.
Rogeting
Rogeting is a neologism created to describe the act of using a synonym listing (such as the Roget's Thesaurus, a famous synonym listing) to "swap" the words of a source text with their synonyms to create an entirely different abstract with the same content. Here's a quick example:
Today I saved a family of cats from the street.
A while ago I rescued a household of mices from the road.
As we can see, it's a rather simple (and highly automatable or scriptable) technique consisting in replacing words with their synonyms, often chosen from a thesaurus or a synonym collection or website. Although anti-plagiarism detection tools would arguably have a hard time trying to detect the original source, the resulting text is often much more complex or difficult to read, especially when the replacement is performed using an automated tool: for this very reason, such attempts often require the subsequent action of human operators to "fix" the rewritten sentences.
The rogeting technique has been developed with the precise intent of "not being detected" by the anti-plagiarism software and it's often used by students (using automatic or even manual approaches) to "cheat" these kinds of tools. The first use of such term has been attributed to Chris Sadler, principal lecturer in business information systems at Middlesex University, who had to deal with various rogeting attempts performed by his students.
Conclusion
That's it, at least for now. In case you're looking for some of the best free plagiarism checker tools available on the web, feel free to check our 10 free anti-plagiarism detection tools article.
