")
Table of Contents
If you've worked in the IT Security field you'll most likely already know what Information Protection actually is and why it became a top priority for all companies in these latest years. In case you don't, here's a quick definition: Information Protection is a set of defined practices put togheter to help organizations discover, classify, label, and protect sensitive documents and emails.
The Information Protection organization guidelines are often enforced by a dedicated document, usually called Information Protection Policy, which provides guidelines to users on the processing, storage and transmission of sensitive information.
The CIA Triad
The main goal of Information Protection is to ensure that all the information managed by the company is appropriately protected from modification or disclosure, thus enforcing the three main rules of data processing - also known as the CIA triad: Confidentiality, Integrity and Availability. Each of these component represents a fundamental objective of information security.
- Confidentiality: Often associated with secrecy and the use of encryption, the term "confidentiality" means that the data should only be available to authorized parties; or, to put the same concept in other words, that the data must not be disclosed to people who do not require them or who should not have access to them. Ensuring confidentiality means that information is organized in terms of who needs to have access, as well as the sensitivity of the data.
- Integrity: Data integrity refers to the certainty that the data is not tampered with or degraded during or after submission; in other words, it guarantees that the data has not been subject to unauthorized modification, either intentional or unintentional. It's worth noting that there are two main points during a tipical data transmission process where the integrity could be compromised: during the upload or transmission of data (in transit) or during the storage of the document in the database or any other physical or logical device (at rest).
- Availability: The term "availability" means that the information must always be available when it is needed. This means that the whole infrastructure used to access the data (Server, Databases, Networks, Firewalls, and so on) must be resilient against power outages, hardware failures, cyber threats, and any other events that might impact the system availability.
The importance of Data Classification
In order to be effective, a good Information Protection Policy must be aware of the Information Lifecycle Management (ILM) processes used by the organization: this means that it must be able to distinguish between different types of data. Such awareness is required to allow System Administrators, Data Protection Officers and Process Owners to effectively answer the following questions:
- What data types are available?
- Where are certain data located?
- What access levels are implemented?
- What protection level is implemented and does it adhere to compliance regulations?
If the organization staff is informed about the data value, the management can better understand which part of the data centre needs to be invested in to keep operations running effectively. This can be of particular importance in risk management, legal discovery, and compliance with government regulations.
Azure Information Protection
Unfortunately, data classification is typically a manual (and long, and boring) process; however, with the help of Artificial Intelligence and Machine Learning algorythms, a number of useful tools from different vendors have been made to help gather information about the data.
However, if you are a Microsoft 365 user and just want to just use the stock solution provided by the vendor, you can start using the Azure Information Protection, a cloud-based platform fully integrated with Microsoft Azure that enables organizations to discover, classify, and protect documents and emails using two powerful features: a unified labeling client and a on-premises scanner.
AIP unified labeling client
The Azure Information Protection unified labeling client can be used to apply data classification to all file types using a labeling system that can be applied from two built-in Windows UI and console tools: File Explorer and PowerShell.
In the following screenshot we can see an example using the File Explorer: the user only needs to right-click to the file(s) he/she wants to classify and select the Classify and protect option to apply the AIP functionality on them:
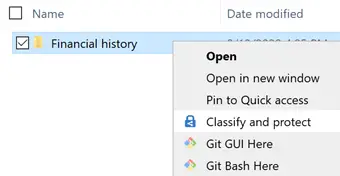
The AIP unified labeling client can be downloaded from the Microsoft Azure Information Protection download page.
AIP on-premises scanner
The AIP scanner is a Windows service that can be installed on any Windows Server with the purpose of discover, classify, and protect files on a number of supported data stores, including the local FileSystem, UNC paths (for network shares that use the SMB or NFS protocols) and SharePoint document libraries; it can basically inspect any files that Windows can index.
When scanning files, the AIP scanner performs the following steps:
- Determine whether files are included or excluded for scanning
- Inspect and label files (possibly using automatic classification - see below)
- Label files that can't be inspected
In order to classify and protect the files, the AIP scanner uses sensitivity labels that can be configured in the Microsoft 365 compliance center. If sensitivity labels have been configured for automatic classification, the scanner can label discovered files to apply that classification, and optionally apply or remove protection.
The great thing about the on-premises scanner is that it can be managed not only using PowerShell, yet also using the Azure Information Protection area within the Azure portal, as shown in the screenshot below:
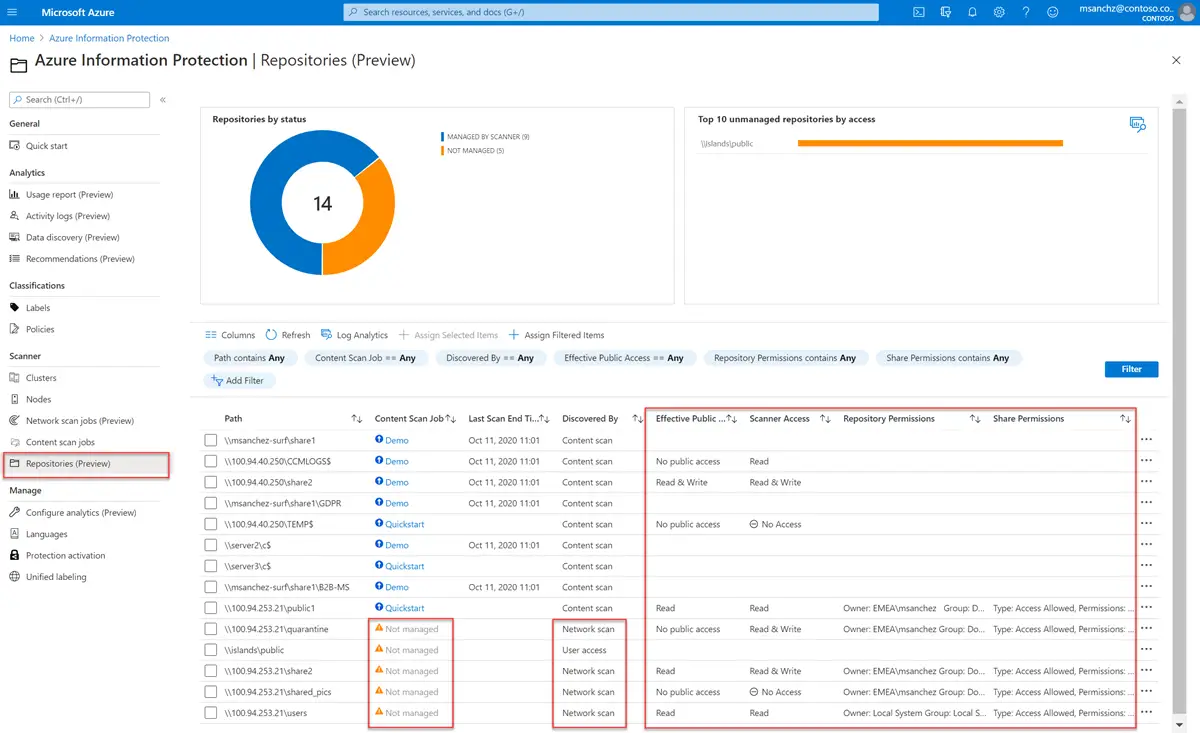
The AIP on-premises scanner can be downloaded from the Microsoft Azure Information Protection download page.
Conclusion
That's it, at least for now: we hope that our general overview of Microsoft Azure Information Protection will help other System Administrators, Data Security Officers and/or Process Owners to choose which set of options to adopt to fullfill and/or automate their Data Classification tasks.
")