
Indice dei contenuti
Negli ultimi anni l'universo del web ha registrato una crescita esponenziale di hacker, malware, ransomware e software dannosi, spesso contraddistinti da un obiettivo comune: trovare un modo per accedere a dati riservati di qualsivoglia tipo, con particolare riguardo a una serie di dati personali immediatamente monetizzabili. Uno scenario che ha reso sempre più importante il ruolo giocato dalla sicurezza informatica all'interno della vita di ognuno di noi, indipendentemente dal lavoro svolto e/o dal ruolo che siamo chiamati a interpretare nella collettività.
La necessità di impedire l'accesso non autorizzato a informazioni personali, sensibili e/o critiche è ormai un'esigenza comune a tutte le principali figure attive sul web a qualsivoglia titolo: utenti finali di siti web, proprietari di servizi, amministratori di server e così via. Le differenze tra queste tipologie di accesso sono legate alla quantità e alla qualità - in termini di valore economico e non - di ciò che dobbiamo proteggere, che determinano inevitabilmente le misure di sicurezza minime che dovremmo adottare per adempiere a tale scopo. Un rapporto, quello tra "valore" del dato e metodologia di protezione adeguata, che non può prescindere da una valutazione del rischio ben eseguita, possibilmente coadiuvata da una attenta analisi costi-benefici: portare a termine questi processi e osservarne i relativi risultati è quasi sempre il modo più efficace per determinare con successo le misure tecniche e organizzative che è opportuno implementare nel nostro scenario specifico.
Non a caso, questa metodologia di azione è consigliata anche dal nuovo Regolamento Generale sulla Protezione dei Dati (GDPR), come chiarito nell'Art. 32 - Sicurezza del trattamento:
Tenendo conto dello stato dell'arte e dei costi di attuazione, nonché della natura, dell'oggetto, del contesto e delle finalità del trattamento, come anche del rischio di varia probabilità e gravità per i diritti e le libertà delle persone fisiche, il titolare del trattamento e il responsabile del trattamento mettono in atto misure tecniche e organizzative adeguate per garantire un livello di sicurezza adeguato al rischio [...]
Ecco un elenco delle misure tecniche e organizzative considerate ad oggi maggiormente efficaci per garantire la protezione e la sicurezza dei dati:
- Controllo degli accessi: proteggere tutti gli accessi fisici al server, client e / o data room con chiavi, chip, card, muri, armadietti, allarmi e simili.
- Minimizzazione: garantire che il personale autorizzato ad accedere ai dati possa farlo solo nei tempi e nei modi necessari allo svolgimento delle proprie loro specifiche attività e / o autorizzazioni, senza poter accedere a nient'altro.
- Integrità: proteggere i dati da perdite accidentali, distruzione o danni di qualsivoglia tipo (naturali e non) utilizzando le contromisure appropriate: sensori fuoco / alluvione, procedure di Disaster Recovery e simili.
- Pseudonimizzazione: sostituire i dati personali non più utilizzati o per i quali è trascorso il tempo di retention dichiarato o previsto dalla legge con caratteri di testo casuali e anonimi, così da mantenerli validi a fini statistici ed eliminando al tempo stesso qualsivoglia informazione personale.
- Crittografia dei dati in-transit (Data Encryption in-transit): adottare le misure necessarie per far sì che i dati vengano sempre trasmessi utilizzando forti standard di crittografia (certificati SSL / TLS) e attraverso connessioni sicure: la medesima attenzione deve essere posta anche suqualsiasi tipo di sito e/o servizio web contenente moduli, schermate di accesso, funzionalità di upload / download e così via.
- Crittografia dei dati at-rest (Data Encryption at-rest): proteggere i dati "a riposo", ovvero memorizzati nelle unità di archiviazione locali (comprese quelle utilizzate dai server e desktop, nonché dai mobile devices) e remote (dati archiviati in Cloud o presso soluzioni SaaS) con algoritmi e sistemi crittografici sufficientemente sicuri.
- Riservatezza: impedire ogni sorta di accesso o elaborazione non autorizzata o illegale dei dati, implementando concetti quali separazione degli ambiti (separation of concerns) e separazione delle attività (separation of duties), adozione di criteri sicuri per quanto riguarda il rilascio di credenziali e password, e così via.
- Recuperabilità: garantire che tutti i dati rilevanti siano soggetti a backup regolari e che i suddetti backup siano controllati regolarmente per garantire il recupero dei dati garantito in caso di furto, smarrimento, danneggiamento o altra tipologia di compromissione.
- Valutazione: adoperarsi affinché l'intero sistema IT sia soggetto a revisioni tecniche periodiche e audit di terze parti, possibilmente con definizione e analisi degli obiettivi e controllo degli indicatori ad essi correlati.
- Auto-Valutazione e aggiornamento: organizzare e/o effettuare corsi di aggiornamento sulla sicurezza informatica e sulle moderne tecniche di protezione e sicurezza dei dati, così da aumentare il know-how comune e ridurre l'eventuale knowledge-gap dei non addetti ai lavori rispetto alle minacce e tipologie di attacco più frequenti.
In questo articolo ci concentreremo su due di queste good practice: Data Encryption in-transit e Data Encryption at-rest, ovvero la protezione crittografica dei dati in movimento e non, lasciando le altre misure di sicurezza a un approfondimento prossimo venturo.
Introduzione: i tre Stati dei Dati Digitali
La prima cosa da fare, quando si parla di dati digitali, è quella di identificare gli "stati" che questi possono effettivamente avere ed essere certi di aver compreso bene il loro significato:
- A riposo (At rest): in altre parole, "non ancora (o non più) in uso o in movimento": si tratta dello stato iniziale (e spesso terminale) della stragrande magioranza dei dati digitali: sinteticamente, possiamo considerare a riposo tutti i dati memorizzati da qualche parte senza essere utilizzati da e/o trasmessi a altri utenti, programmi e applicativi, servizi di terze parti, strumenti per la riproduzione di media digitali, e così via. Tutti i dati memorizzati su qualsiasi unità di archiviazione locale o remota appartengono a questa categoria: da quelli contenuti negli Hard-Disk del nostro PC alla memoria del nostro smartphone; dalle pendrive USB ai backup effettuati sulle nostre unità di archiviazione locali o sui server di rete; dalle memorie di una macchina fotografica agli archivi logici dei database server installati presso la nostra web farm o in cloud; e così via. Più in generale, possiamo ragionevolmente affermare che un dato è a riposo in tutte le situazioni in cui non sta venendo utilizzato e/o trasmesso.
- In movimento (In transit): in altre parole, "in trasmissione". Come suggerisce la parola, si tratta dello stato che i dati acquisiscono nel momento in cui vengono trasmessi a qualcuno o a qualcosa, diventando così oggetto di un data transfer. Si noti che il numero o la tipologia dei soggetti del trasferimento è del tutto irrilevante: può trattarsi di due utenti che si scambiano messaggi di testo tramite una app di chat (da utente a utente); della copia del contenuto di una pendrive USB su un hard-disk locale (da macchina a macchina); dello streaming di una trasmissione televisiva a migliaia di persone contemporaneamente (da una macchina verso molti utenti); dall'inserimento di una transazione all'interno di una blockchain (da un utente verso molte macchine e utenti); e così via.
- In uso (In use): vi sono alcuni casi in cui il dato, pur non essendo in trasmissione, non può essere definito a riposo: pensiamo ad esempio al momento in cui un programma di elaborazione di immagini sta caricando una delle nostre foto nella memoria del nostro computer; oppure, alla riproduzione di un file multimediale (un film o brano musicale) memorizzato in precedenza sulla scheda SD del nostro smartphone e quindi riprodotto grazie una app media player. I dati presenti in questo particolare "stato" vengono definiti in uso nella misura in cui vengono caricati in memoria di un qualsiasi dispositivo elettronico al fine di essere "letti e interpretati" da applicativi presenti su quello stesso sistema. Ovviamente, si tratta di una condizione che può essere resa più o meno attaccabile a seconda delle particolari modalità di caricamento e lettura utilizzate dal software di riproduzione e/o dalle componenti hardware e software del sistema utilizzato: a seguito delle recenti vulnerabilità di sicurezza che consentivano di aggredire i dati quando si trovano in questo stato (SPECTRE e MELTDOWN), sia i moderni sistemi operativi che le principali componenti hardware dei moderni computer utilizzano tecniche particolari per proteggere le proprie aree di memoria da accessi non autorizzati. Al tempo stesso, proteggere i dati in uso da parte dell'utente è particolarmente complesso e in molti casi impossibile, in quanto qualsiasi contromisura rischierebbe di provocare malfunzionamenti o crash dell'applicativo software o hardware che li sta utilizzando: l'unica contromisura che è realisticamente possibile adottare è la buona pratica del costante aggiornamento del proprio sistema attraverso i canali ufficiali di distribuzione di firmware, patch e update. Per questo motivo in questo articolo non ci occuperemo ulteriormente di questa particolare tipologia di stato, dando per scontato l'utilizzo da parte del lettore di software certificati e sistemi operativi sicuri e costantemente aggiornati.
La somma di questi tre stati è nota come "the Three Stages of Digital Data", ovvero "i Tre Stati dei Dati Digitali": ora che abbiamo compreso le loro definizioni e sappiamo come distinguerli, siamo pronti per analizzare nel dettaglio i primi due.
Data Encryption at-rest
La definizione di at-rest che abbiamo dato nel paragrafo precedente ci consente di comprendere come questa tipologia di dati si trovi tipicamente in una situazione di stabilità: i dati a riposo non sono coinvolti in una trasmissione e non vengono utilizzati dal sistema, quindi possiamo assumere che, almeno per il momento, abbiano raggiunto la loro destinazione.
Perché utilizzarla
Visto che questi dati non vengono trasmessi né utilizzati, perché mai dovremmo prenderci la briga di crittografarli? In realtà ci sono un sacco di buone ragioni per farlo. I dati at-rest sono statisticamente quelli più a rischio, proprio perché vengono spesso trascurati: alcuni esempi? I backup effettuati su supporti mobili (CD-ROM, DVD, BLU-RAY o anche hard-disk USB), che sono spesso alla mercé del primo ladro che dovesse malauguratamente penetrare all'interno della nostra abitazione (o ufficio); le foto presenti sul nostro cellulare, che può essere "facilmente" smarrito o rubato; e così via. Tutte situazioni in cui, in mancanza di una adeguata protezione, rischiamo di trovarci in un istante vittime di un data breach di entità e gravità spesso elevate, talvolta persino difficili da quantificare.
Furto fisico
Entrambi gli esempi che abbiamo fatto poche righe fa contemplano la possibilità che i nostri dati vengano rubati in modo fisico, ovvero mediante l'appropriazione indebita del dispositivo di archiviazione che li ospita. In tutti questi casi, il Data Encryption at-rest costituisce una importante misura di sicurezza in quanto impedisce al ladro di poter immediatamente fruire di quei dati. Ovviamente si tratta di una contromisura temporanea, poiché nulla potrà impedire l'utilizzo di software specifici per avere la meglio sull'algoritmo di cifratura mediante tecniche di cracking e/o brute-force... ma si tratta di operazioni estremamente complesse, che richiedono necessariamente un know-how specifico e grande quantità di tempo (settimane, mesi, in alcuni casi anni): tempo che va a tutto vantaggio di chi ha subito il furto, che potrà adoperarsi per cambiare eventuali password, avvisare i proprietari dei dati sottratti, e compiere qualsiasi altra contromisura per minimizzare i danni dovuti al data breach.
Furto logico
Tutte le volte che un nostro PC, smartphone, sito web, e-mail o altro strumento su cui abbiamo memorizzato dati subisce un attacco informatico di qualsivoglia tipo (hacker, virus, malware, ransomware, et sim.), rischiamo di trovarci in una situazione molto simile a quella del furto fisico... con l'aggravante ulteriore che spesso è molto difficile accorgersene, sia per gli amministratori di sistema che per i "normali" utenti, visto che non sarà avvertita alcuna mancanza e tutto sembrerà funzionare correttamente. Una situazione di unawareness, ovvero di mancata consapevolezza del danno subito, fotografata alla perfezione dalla seguente celebre frase di John T. Chambers, storico CEO di Cisco, Inc.:
There are two types of companies: those that have been hacked, and those who don't know they have been hacked.
Esistono due tipi di aziende: quelle che hanno subito una violazione informatica, e quelle che non sanno di aver subito una violazione informatica.
Se consideriamo la situazione attuale di internet, caratterizzata dala crescita esponenziale di malware, ransomware e tentativi di attacco hacker a qualsiasi dispositivo connesso a internet, possiamo ragionevolmente considerare questa affermazione valida non soltanto per aziende, ma per qualsiasi tipologia di utente.
Errore umano
I furti fisici e/o logici non sono gli unici scenari in cui la crittografia dei dati a riposo può rivelarsi un efficace strumento di prevenzione: in uno degli esempi fatti in precedenza abbiamo menzionato non a caso la possibilità di smarrimento del nostro smartphone, che rischia di esporre i dati ivi contenuti alle stesse criticità di un furto. Lo stesso può dirsi per un errore di configurazione, ad esempio una errata assegnazione di permessi e/o credenziali a un utente di un nostro sito o servizio tale da consentirgli l'accesso a dati che non dovrebbe essere autorizzato a trattare; per non parlare dei rischi connessi a un modo superficiale di gestire e memorizzare le nostre credenziali, che potrebbe dar modo qualcuno dei nostri amici, parenti o conoscenti (quando non a perfetti sconosciuti) di accedere ai nostri sistemi e/o applicativi a nostra insaputa. In tutti questi casi la data encryption at-rest risulta essere una contromisura particolarmente efficace, anche perché si tratta spesso di accessi che avvengono all'interno di finestre temporali relativamente ristrette.
A cosa serve
Tenendo conto di tutte le situazioni descritte fino ad ora, possiamo affermare che adottare un sistema di data encryption at-rest per i nostri dati personali può esserci di grande aiuto per ridurre i rischi e i danni connessi a un possibile Data Breach. Inutile dire che, nella maggior parte dei casi, non ci aiuterà nelle attività di prevenzione - che sono più legate all'utilizzo di strumenti di sicurezza come firewall, antivirus/antimalware, good practice e protocolli di accesso ben congegnati - ma ci darà senz'altro la possibilità (e il tempo, cosa tutt'altro che trascurabile) per mettere in atto le contromisure del caso.
Come implementarla
Implementare una metodologia di Data Encryption at-rest per i nostri dati personali può essere un'attività estremamente semplice o molto complessa, a seconda di una serie di fattori e variabili che è opportuno mettere a fuoco:
- quali e quanti strumenti di memorizzazione dati fisici e logici vogliamo (o dobbiamo) proteggere: gli strumenti fisici includono gli Hard Disk, i NAS, le memorie interne e esterne degli smartphone, pendrive USB e così via; gli strumenti di archiviazione logica includono database locali o remoti, la maggior parte dei sistemi di archiviazione in cloud, dispositivi virtualizzati, e così via;
- chi avrà necessità di avere accesso ai dati criptati: esseri umani (includendo sia gli operatori locali che gli utenti remoti che si connettono ai nostri servizi), strumenti software utilizzati manualmente (come i classici Word, Excel o Photoshop), processi o servizi automatici (come i classici software di backup quotidiani o gli strumenti di sincronizzazione in tempo reale, come ad es. l'applicativo Google Drive Sync);
- Quanto siamo disposti a sacrificare, in termini di performance e/o di semplicità d'accesso ai dati, per incrementare la sicurezza degli stessi: possiamo aspettarci ragionevolmente che i nostri utenti, collaboratori e/o familiari (nonché noi stessi, ovviamente) siano disposti a utilizzare degli strumenti di decrypt (manuali o anche automatizzati) per poter accedere ai dati di loro interesse? Dovremmo utilizzare un sistema di cifratura protetto da password, public/private key, token fisico o codice OTP? Abbiamo la possibilità di implementare una encryption che sia sufficientemente "trasparente" da non inibire la possibilità ai nostri utenti/collaboratori, nonché ai nostri software, di gestire questi dati senza particolari problemi?
Per nostra fortuna i moderni software di data encryption sono in grado di rispondere in modo più che soddisfacente alla maggior parte di queste domande, in quanto sono stati costruiti proprio per proteggere i nostri dati senza compromettere il funzionamento dei sistemi che, presumibilmente, necessitano di accedervi con regolarità. Ad esempio:
- se abbiamo bisogno di proteggere Hard Disk o supporti come CD-ROM, DVD-ROM e BLU-RAY, possiamo utilizzare strumenti come VeraCrypt (100% free) o AxCrypt (versione gratuita disponibile, con alcune limitazioni);
- se abbiamo necessità di proteggere le nostre pendrive USB, possiamo utilizzare gli strumenti di cui sopra o addirittura dotarci di una delle molte interfacce USB dotate di sistemi di cifratura hardware: questi dispositivi funzionano solitamente tramite password o impronta digitale (fingerprint) e si trovano in commercio a partire da 20-30 EUR;
- se vogliamo proteggere dati memorizzati su uno o più Database, è sufficiente orientare la scelta su uno dei tanti DBMS open-source o commerciali disponibili oggi sul mercato che forniscono funzionalità di data encryption native (MySQL e MariaDB con la loro InnoDB tablespace encryption, MSSQL mediante la Transparent Data Encryption, e così via);
- se cerchiamo un modo efficace per proteggere il nostro archivio E-Mail, è molto probabile che il nostro client e-mail supporti qualche plug-in, add-on o funzionalità nativa che ci consenta di utilizzare i protocolli S/MIME o PGP (entrambi gratuiti): anche se si tratta di tecniche più legate al paradigrma della data encryption in-transit, visto che proteggono dati che si prevede vengano trasferiti tra mittente e destinatario, nella pratica dei fatti entrambi svolgono un lavoro di encryption client-side e quindi consentono di proteggere i messaggi di posta anche quando sono/diventano at-rest. Inutile dire che, poiché questi messaggi dovranno essere scritti e letti da utenti diversi, è fondamentale che mittente e destinatario si mettano d'accordo su quale protocollo utilizzare e configurino il loro client e-mail in modo compatibile: un prerequisito, quello della compatibilità degli algoritmi di cifratura utilizzati, comune anche a tutte le principali tecniche di data encryption in-transit, alle quali è dedicato il prossimo paragrafo.
Data Encryption in-transit
Come suggerisce il nome, i dati in-transit sono quelli che si trovano "in viaggio" da un nodo all'altro posti all'interno di una rete attraverso in un flusso o canale di trasmissione: un tipico esempio di dati in-transit è dato dalle dinamiche che avvengono tra il nostro browser e un qualsiasi sito web che visitiamo durante una nostra sessione di navigazione. Ecco, in estrema sintesi, cosa avviene dietro le quinte:
- Il nostro computer, attraverso un browser web come Google Chrome, Firefox o Edge, invia una HTTP (o HTTPS) request al server che ospita il sito web che vogliamo visitare.
- Il server accetta la nostra request, identifica la risorsa (statica o dinamica) che abbiamo richiesto, quindi la invia al nostro browser sotto forma di HTTP (or HTTPS) response sulla medesima porta TCP utilizzata per effettuare la request (tipicamente la porta 80 per le connessioni HTTP e la porta 443 per le connessioni HTTPS).
- Il nostro browser riceve la HTTP(s) response, la memorizza (se previsto) all'interno della sua cache e infine la mostra su schermo, consentendoci di visualizzare i dati richiesti.
Come si può vedere, il tutto è possibile solo attraverso una trasmissione di dati che avviene tra il server che ospita il sito web e il client, ovvero il nostro browser: durante questa comunicazione, il flusso di dati richiesto (in questo caso una singola pagina web, tipicamente in codice HTML) attraversa almeno cinque stati diversi in pochi istanti:
- inizia come at-rest (nel dispositivo di memorizzazione dati del server)
- da at-rest a in-use (la memoria del server)
- da in-use a in-transit (tramite il protocollo HTTP, su porta TCP)
- da in-transit a nuovamente in-use (la memoria del nostro browser)
- infine, nuovamente at-rest (la cache del browser).
Perché utilizzarla
Ora, diamo per scontato che sia il server che il client abbiano implementato un livello adeguato di data encryption at-rest: questo significa che il primo e il quinto stato tra quelli elencati sopra sono ben protetti da un tentativo di intrusione. Al tempo stesso, però, il terzo stato - quello in cui i dati sono in-transit - potrebbe essere vulnerato, in quanto il suo livello di encryption dipende unicamente dai protocolli di trasmissione utilizzati: in altre parole, il suo livello di protezione non è garantito.
Ecco ciò che succede dietro le quinte quando la trasmissione avviene mediante un protocollo di trasmissione non sicuro, ovvero che non garantisce l'encryption dei dati in-transit:
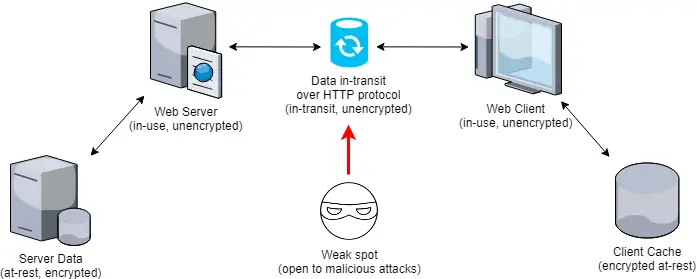
Come si può vedere, siamo di fronte a una falla di sicurezza piuttosto evidente: nel momento in cui il web server si trova a dover gestire la request in ingresso, ha necessità di recuperare i dati protetti da encryption at-rest e di decodificarli in memoria subito prima di inviarli attraverso il canale HTTP: quei dati saranno nuovamente protetti solo quando giungeranno a destinazione. Viene così a crearsi un vero e proprio weak spot (punto debole) durante lo stato in-transit dei dati stessi, che potrebbe cadere preda di attacchi di natura malevola volti a impadronirsi di quelle informazioni.
A cosa serve
La tipologia di attacchi che possono essere usati per sottrarre dati che transitano attraverso un protocollo di trasmissione non sicuro come HTTP è molto ampia, ma generalmente riconducibile a due tipologie principali:
- Eavesdropping (intercettazione): un attacco che avviene a livello di rete, volto alla cattura di singoli pacchetti di trasmissione (per maggiori informazioni, leggi qui).
- Man-in-the-Middle: un attacco basato sul tampering (manomissione) dei servizi o dell'infrastruttura di comunicazione, mediante il quale l'attaccante si intromette segretamente nella comunicazione tra due peer (ad es. il server e il client) guadagnando l'accesso ai dati trasmessi e, in taluni casi, apportando persino delle modifiche alla comunicazione (per maggiori informazioni, leggi qui).
La risposta giusta per prevenire questo tipo di attacchi è dunque quella di implementare un protocollo di encryption in-transit, così da rendere più sicuri i dati che trasmettiamo e riceviamo.
Come implementarla
Nella maggior parte dei casi, il modo migliore per implementare un protocollo di data encryption in-transit è quello di configurare i propri strumenti di trasmissione e ricezione dati basandosi su un set di regole e best-practice prestabilite dai principali standard di sicurezza informatica: nello specifico, si tratta di stabilire in modo oculato quali protocolli adottare e quali evitare, quali software utilizzare e quali evitare, e così via. Alcuni esempi:
- In tutti i casi in cui ci connettiamo a un server attraverso una interfaccia di rete, qualsiasi dato e/o file personale o potenzialmente riservato dovrebbe essere trasmesso utilizzando protocolli crittografici come il Secure Sockets Layer (SSL) e standard di trasmissione sicuri come il Transport Layer Security (TLS): questo tipo di approccio non è esclusivo dei siti web e delle connessioni HTTP in generale ma può essere implementato anche su connessioni di tipo FTP, POP3, SMTP, IMAP e così via. Ad oggi, il modo più semplice ed economico per implementare un servizio di trasmissione TLS è quello di dotarsi di un certificato SSL/TLS HTTPS e configurarlo sul servizio che si occupa di stabilire la connessione: i certificati possono essere acquistati dalle Certification Authorities (Comodo, GlobalSign, GoDaddy, DigiCert e loro rivenditori/distributori) oppure auto-generali attraverso un processo di self-signing, come abbiamo spiegato in questo articolo. Inutile dire che, benché i certificati auto-firmati possano essere configurati per offrire lo stesso livello di encryption delle controparti rilasciate dalle Certification Authority più blasonate, risulteranno inefficaci se utilizzati su siti e/o servizi liberamente accessibili sul web per via della mancanza della green bar / green lock (e della presenza dei warning rossi mostrati da tutti i browser principali): per questo motivo l'utilizzo dei certificati auto-firmati è solitamente limitato ai siti e/o servizi amministrativi interni o comunque non aperti al pubblico.
- In tutti i casi in cui siamo costretti a inviare dati testuali personali o riservati tramite e-mail dovremmo utilizzare strumenti di encryption appositi come S/MIME o PGP, di cui abbiamo già avuto modo di parlare nel paragrafo dedicato all'encryption at-rest: pur trattandosi di protocolli di sicurezza che lavorano a livello client (e quindi, tecnicamente, at-rest) sono estremamente utili per proteggere le informazioni contenute all'interno di un messaggio e-mail anche quando queste cambiano stato (diventando in-transit).
- In tutti i casi in cui ci troviamo a trasferire dei file allegandoli a una e-mail e/o utilizzando sistemi di file-storage in cloud o che risiedono su servizi terzi, dovremmo utilizzare dei sistemi di protezione (basati su data encryption, ovviamente) sui suddetti file. La maggior parte dei formati di compressione file oggi utilizzati - tra cui ZIP, RAR e 7Z - supportano la possibilità di effettuare la crittografia dei file compressi all'interno di un archivio: prendere l'abitudine di utilizzare questa funzionalità ha il doppio vantaggio di proteggere i propri allegati da accessi non autorizzati (eavesdropping, man-in-the-middle) e ridurre le dimensioni del pacchetto di file trasmessi. Visto che ci siete, abbiate cura di scegliere protocolli di encyrption sicuri e password sufficientemente complesse, visto che quegli archivi - qualora dovessero cadere in mani sbagliate - potrebbero essere oggetto di tecniche di brute-force estremamente sofisticate, visto che l'attacker non dovrà preoccuparsi di non farsi scoprire e non sarà in alcun modo limitato nel numero di tentativi effettuabili per singola unità di tempo.
- Tutte le trasmissioni di dati (testuali e binari) che non avvengono tramite il web dovrebbero essere protette attraverso protocolli di data-encryption a livello applicativo, prendendo in considerazione le seguenti possibilità:
- Se i dati provengono da un database che risiede al di fuori del perimetro della web farm, le connessioni tra l'applicativo e il database dovrebbero essere protette utilizzando algoritmi di crittografia in standard FIPS o altri criteri di protezione che impediscano attacchi al canale di trasmissione/ricezione dati.
- In tutti i casi in cui una protezione applicativa non sia disponibile, implementare sistemi di protezione a livello di rete (IPSec o SSH), e/o limitare le possibilità di connessione ai soli dispositivi autorizzati, ovvero alle sole interfacce di rete note, o tramite protocolli sicuri (es. VPN): tali accorgimenti possono essere implementati senza eccessive difficoltà mediante opportune configurazioni del proprio firewall.
La tabella seguente mostra una serie di esempi di protocolli di comunicazione considerati "non sicuri" e quindi da evitare, affiancati dal corrispettivo "sicuro" che è invece opportuno e preferibile utilizzare:
| Transfer Type | What to avoid (insecure) | What to use (secure) |
|---|---|---|
| Web Access | HTTP | HTTPS |
| E-Mail Servers | POP3, SMTP, IMAP | POP3S, IMAPS, SMTPS |
| File Transfer | FTP, RCP | FTPS, SFTP, SCP, WebDAV over HTTPS |
| Remote Shell | telnet | SSH2 |
| Remote Desktop | VNC | radmin, RDP |
Data Encryption End-to-End
Le tecniche di protezione crittografica in-transit possono essere molto utili, specialmente in determinati contesti. Tuttavia, nella maggior parte dei casi sono contraddistinte da una debolezza intrinseca che, in taluni casi, può avere pesanti implicazioni in termini di sicurezza delle informazioni: non garantiscono che il dato resti crittografato durante l'intero percorso che separa il trasmittente e il ricevente, ovvero i due (o più) peer coinvolti nel processo di comunicazione. Per dirla in altre parole, la cifratura e la decodifica del dato avvengono spesso al di fuori del contesto applicativo degli attori coinvolti nella comunicazione, dando così vita a una sorta di "ultimo miglio" (uno o più) che il dato è costretto a percorrere in chiaro.
Un perfetto esempio di questa tipologia di trasmissione è proprio quella prevista dal protocollo HTTPS/TLS, che si basa su una strategia crittografica definita non a caso link encryption (o online encryption) proprio per distinguerla dalla end-to-end encryption (E2E): questa tecnica prevede che il traffico dati venga crittografato e decrittato solo mentre attraversa il canale di comunicazione principale, ma non quando raggiunge gli endpoint responsabili della connessione - dove risiedono fisicamente le chiavi crittografiche necessarie per decodificare i dati. Questo significa che esistono dei weak-point sfruttando i quali i nostri dati potrebbero ancora subire un attacco da parte di eavesdropper più o meno coinvolti nei processi di connessione: si pensi ad esempio agli internet service provider che controllano il traffico dall'endpoint server al peer, oppure agli hosting provider che hanno modo di accedere ai server contenenti le chiavi di sicurezza necessarie per decrittare i dati, e così via.
La End-to-End Encryption (E2EE) consente di superare queste limitazioni mediante un pattern implementativo che prevede che i dati vengano crittografati e decrittati a livello applicativo dai singoli client, senza che alcun agente esterno venga a contatto con le chiavi crittografiche o i dati in chiaro.
Perché utilizzarla
Per comprendere meglio il funzionamento della encryption end-to-end e il maggiore livello di protezione rispetto alla encryption in-transit per quanto riguarda l'attività di potenziali eavesdropper, prendiamo a esempio i seguenti scenari:
- Supponiamo che un attacker riuscisse a installare un certificato root nel server di una Certificate Authority considerata "sicura" e con un livello di trust elevato: questa operazione, di per sé molto improbabile, potrebbe essere il risultato di una forzatura operata dal governo e/o dalle forze di polizia, o magari da un operatore corrotto che sia impiegato presso quella medesima CA. In ogni caso, chiunque riuscisse a mettere a segno un colpo del genere potrebbe effettuare attacchi di tipo man-in-the-middle sulla connessione TLS, intercettando la comunicazione ed eventualmente persino alterandola (tampering). Con una encryption di tipo end-to-end questo sarebbe impossibile, poiché la encryption non viene effettuata a livello di server.
- La encryption end-to-end può anche essere utilizzata per aumentare i criteri di sicurezza all'interno delle singole operazioni compiute dai vari thread e processi interni al sistema operativo. Chi si ricorda delle recenti falle di sicurezza denominate SPECTRE e MELTDOWN? Entrambe potevano essere utilizzate da un processo "malevolo" per leggere dati e informazioni provenienti da altri processi: uno scenario particolarmente critico se si verifica all'interno di server caratterizzati da un elevato livello di segregation of duties (si pensi a un data server che gestisce più archivi relativi a diversi clienti). La presenza di una encryption end- to-end interna ai singoli processi potrebbe evitare problematiche di questo tipo, impedendo ai dati non crittografati di essere caricati in memoria.
Come può aiutarci
In termini di protezione delle informazioni da accessi non autorizzati gli strumenti di comunicazione basati su encryption end-to-end sono senza ombra di dubbio i metodi più sicuri che possono essere utilizzati con le tecnologie attuali, in quanto sono gli unici a garantire che i dati trasmessi saranno fruibili solo dal destinatario finale. Per questo motivo sempre più servizi che hanno basato il core business sulle comunicazioni informatiche hanno implementato algoritmi di encryption end-to-end all'interno dei propri client: tra questi possiamo includere Whatsapp, LINE, Telegram, e una serie di altri protagonisti del settore.
Per ulteriori dettagli sul funzionamento della crittografia end-to-end consigliamo di consultare questa pagina della guida di Whatsapp e, soprattutto, il Whatsapp Security White Paper, che contiene numerosi dettagli sulle modalità di implementazione della stessa.
Come implementarla
La crittografia end-to-end può essere utilizzata per proteggere qualsiasi tipo di comunicazione: messaggi di chat, file, foto, dati ottenuti tramite l'utilizzo di dispositivi IoT, permanenti o temporanei. E' anche possibile effettuare una crittografia parziale, selezionando quali dati vogliamo crittografare in modalità end-to-end e quali trasmettere in chiaro o con altre tecniche crittografiche. Ad esempio, nel caso delle chat, potremmo decidere di trasmettere in plain-text informazioni grossomodo "neutre" come i timestamp di invio e ricezione dei messaggi, riservando gli strumenti di protezione più avanzati al solo contenuto dei singoli messaggi.
I passaggi implementativi necessari sono quelli tipici della crittografia asimmetrica: ogni utente dispone di una coppia di chiavi: una chiave pubblica, che sarà recuperata e utilizzata dai suoi interlocutori per crittografare i messaggi a lui rivolti, e una chiave privata, necessaria per decodificare i messaggi ricevuti (e crittografati con la chiave pubblica). Queste chiavi vengono generate dal software (la app di chat) e memorizzate all'interno del dispositivo dell'utente al momento dell'accesso o al successivo accesso al servizio.
In caso di una chat a due (P2P), la gestione delle chiavi pubbliche è solitamente delegata al server, che si occupa di trasmettere la chiave pubblica relativa a ciascun utente ai suoi interlocutori nel momento in cui questi ultimi manifestano l'intenzione di inviare dei dati. Nel caso di una chat di gruppo, l'implementazione più diffusa è solitamente più complessa e funziona grossomodo così:
- al momento della creazione del gruppo, il client dell'utente che crea il gruppo genera una coppia di chiavi ad-hoc, che vengono associate in modo univoco al gruppo in questione.
- nel momento in cui ciascun utente viene invitato e accetta di entrare nel gruppo, il client dell'utente che ha spedito l'invito recupera la chiave pubblica del nuovo utente e la utilizza per crittografare la chiave privata del gruppo, che viene inviata al nuovo arrivato tramite la crittografia end-to-end "a due" secondo le modalità descritte sopra.
- Il client del nuovo utente, nel momento in cui riceve la chiave privata del gruppo, diventa in grado sia di inviare i messaggi (crittografandoli con la chiave pubblica del gruppo) che di decrittarli (utilizzando la chiave privata del gruppo): si noti che, poiché il suo client possiede entrambe le chiavi, il nuovo utente ha anche la possibilità di invitare a sua volta nuovi membri, a patto di essere in possesso dei permessi necessari a compiere tale operazione.
Nelle implementazioni più recenti, il meccanismo di encrypt/decrypt dei messaggi di una chat basata sull'encryption end-to-end possono essere resi più efficienti attraverso l'utilizzo di un sistema di crittografia ibrido, ovvero basato sull'utilizzo congiunto di crittografia asimmetrica (basata su una coppia di chiavi - la pubblica per crittografare, la privata per decrittare) e crittografia simmetrica (basata su una singola chiave per entrambe le operazioni): in questi sistemi la crittografia asimmetrica viene solitamente utilizzata soltanto per scambiarsi la singola chiave simmetrica, la quale viene poi utilizzata per le attività di encryption e decryption relative a tutte le trasmissioni successive.
Conclusioni
Il nostro viaggio attraverso le molteplici tipologie di crittografia è giunto al termine: ci auguriamo che questa panoramica possa essere d'aiuto agli utenti e agli amministratori di sistema interessati ad approfondire questo importantissimo argomento.


